SQL is one of the most in-demand skills that you find in job descriptions from the data domain industry, whether you’re applying for a data analyst, a data engineer, a data scientist, or any other role.
To demonstrate the importance of SQL for data-related jobs, I have analyzed more than 72,000 job listings on Indeed, looking at key skills mentioned in job posts with “data” in the title.
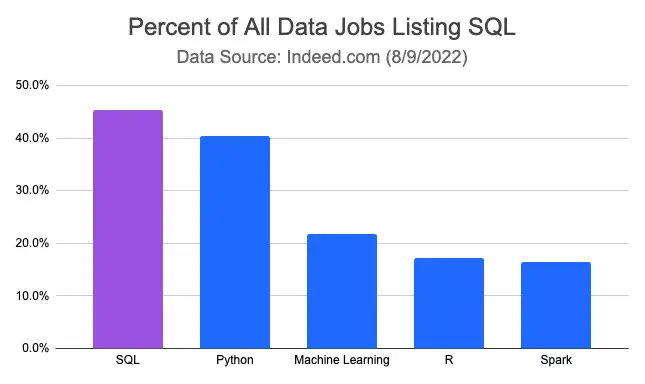
As we can see, SQL is the most in-demand skill among all jobs in data, appearing in 45.4% of job postings.
Interestingly, the proportion of data jobs listing SQL has been increasing! I performed this same analysis multiple times over the years, and here’s what I found:
- 2017: 35.7% (SQL #1)
- 2021: 42.7% (SQL #1)
- 2022: 45.4% (SQL #1)
But why exactly is it that it is so frequently used. And why isn’t it dead even though it has been around for such a long time?
There are several reasons: one of the main reasons would be that companies mostly store data in Relational Database Management Systems (RDBMS) or in Relational Data Stream Management Systems (RDSMS) and you need SQL to access that data. SQL is the lingua franca of data: it gives you the ability to interact with almost any database or to even build your own locally!
Write Fast SQL Query
SQL is a declarative language, that is, each query declares what we want the SQL engine to do, but it doesn’t say how. As it turns out, the how — the “plan” — is what affects the efficiency of the queries, however, so it’s pretty important.
An inefficient query will drain the production database’s resources, and cause slow performance or loss of service for other users if the query contains errors. It’s vital you optimize your queries for minimum impact on database performance.
There is no step-by-step guide for the same. In turn, we must use general guidelines for writing queries, and which operators to use.
Benefits of Query Optimization
- Minimize production issues: Inefficient queries require high CPU, memory, and I/O operations that mostly lead to deadlocks, failed transactions, system hangs, and other production issues.
- Performance issues: Slow query means slower response time of applications using the query, which results in poor user experience.
- Save infra cost: As non-optimized query requires more CPU and memory, they lead to higher infrastructure cost.
Query Optimization Best Practices
Some of the commonly used tips to optimize SQL queries are
Query 1: Use Column Names Instead of * in a SELECT Statement
If you are selecting only a few columns from a table there is no need to use SELECT *. Though this is easier to write, it will cost more time for the database to complete the query. By selecting only the columns you need, you are reducing the size of the result table, reducing the network traffic, and also in turn boosting the overall performance of the query.
| Original Query | Improved Query |
|---|---|
| SELECT * FROM SH.Sales; | SELECT s.prod_id FROM SH.sales s; |
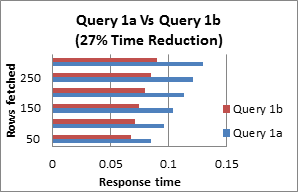
Query 2: Avoid including a HAVING clause in SELECT statements
The HAVING clause is used to filter the rows after all the rows are selected and it is used like a filter. It is quite useless in a SELECT statement. It works by going through the final result table of the query parsing out the rows that don’t meet the HAVING condition.
| Original Query | Improved Query |
|---|---|
| SELECT s.cust_id,count(s.cust_id) FROM SH.sales s GROUP BY s.cust_id HAVING s.cust_id != ‘1660’ AND s.cust_id != ‘2’; | SELECT s.cust_id,count(cust_id) FROM SH.sales s WHERE s.cust_id != ‘1660’ AND s.cust_id !=’2′ GROUP BY s.cust_id; |
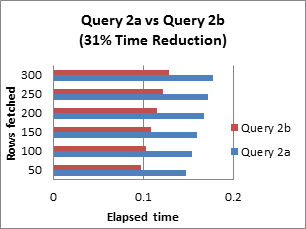
Query 3: Eliminate Unnecessary DISTINCT Conditions
Considering the case of the following example, the DISTINCT keyword in the original query is unnecessary because the table_name contains the primary key p.ID, which is part of the result set.
| Original Query | Improved Query |
|---|---|
| SELECT DISTINCT * FROM SH.sales s JOIN SH.customers c ON s.cust_id= c.cust_id WHERE c.cust_marital_status = ‘single’; | SELECT * FROM SH.sales s JOIN SH.customers c ON s.cust_id = c.cust_id WHERE c.cust_marital_status=’single’; |
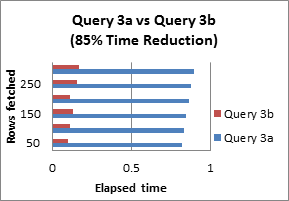
Query 4: Un-nest subqueries
Rewriting nested queries as joins often leads to more efficient execution and more effective optimization. In general, sub-query un-nesting is always done for correlated sub-queries with, at most, one table in the FROM clause, which is used in ANY, ALL, and EXISTS predicates. An uncorrelated sub-query, or a sub-query with more than one table in the FROM clause, is flattened if it can be decided, based on the query semantics, that the sub-query returns at most one row.
| Original Query | Improved Query |
|---|---|
| SELECT * FROM SH.products p WHERE p.prod_id = (SELECT s.prod_id FROM SH.sales s WHERE s.cust_id = 100996 AND s.quantity_sold = 1 ); | SELECT p.* FROM SH.products p, sales s WHERE p.prod_id = s.prod_id AND s.cust_id = 100996 AND s.quantity_sold = 1; |
Query 5: Consider using an IN predicate when querying an indexed column
The IN-list predicate can be exploited for indexed retrieval and also, the optimizer can sort the IN-list to match the sort sequence of the index, leading to more efficient retrieval. Note that the IN-list must contain only constants or values that are constant during one execution of the query block, such as outer references.
| Original Query | Improved Query |
|---|---|
| Original query: SELECT s.* FROM SH.sales s WHERE s.prod_id = 14 OR s.prod_id = 17; | SELECT s.* FROM SH.sales s WHERE s.prod_id IN (14, 17); |
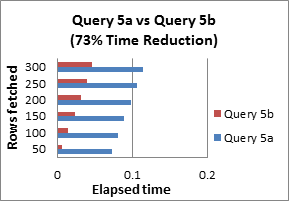
Query 6: Use EXISTS instead of DISTINCT when using table joins that involve tables having one-to-many relationships
The DISTINCT keyword works by selecting all the columns in the table and then parsing out any duplicates. Instead, if you use a sub query with the EXISTS keyword, you can avoid having to return an entire table.
| Original Query | Improved Query |
|---|---|
| SELECT DISTINCT c.country_id, c.country_name FROM SH.countries c,SH.customers e WHERE e.country_id = c.country_id; | SELECT c.country_id, c.country_name FROM SH.countries c WHERE EXISTS (SELECT ‘X’ FROM SH.customers e WHERE e.country_id = c.country_id); |
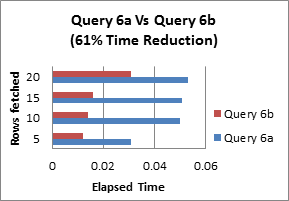
Query 7: Try to use UNION ALL in place of UNION
The UNION ALL statement is faster than UNION, because UNION ALL statement does not consider duplicates, and the UNION statement does look for duplicates in a table while selecting rows, whether or not they exist.
| Original Query | Improved Query |
|---|---|
| SELECT cust_id FROM SH.sales UNION SELECT cust_id FROM customers; | SELECT cust_id FROM SH.sales UNION ALL SELECT cust_id FROM customers; |
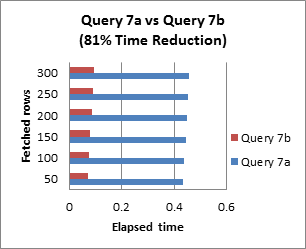
Query 8: Avoid using OR in join conditions
Any time you place an ‘OR’ in the join condition, the query will slow down by at least a factor of two.
| Original Query | Improved Query |
|---|---|
| SELECT * FROM SH.costs c INNER JOIN SH.products p ON c.unit_price = p.prod_min_price OR c.unit_price = p.prod_list_price; | SELECT * FROM SH.costs c INNER JOIN SH.products p ON c.unit_price = p.prod_min_price UNION ALL SELECT * FROM SH.costs c INNER JOIN SH.products p ON c.unit_price = p.prod_list_price; |
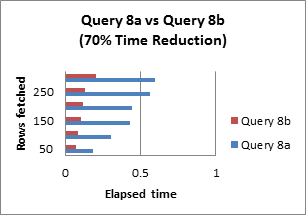
Query 9: Avoid functions on the right-hand side of the operator
Functions or methods are used very often with their SQL queries. Rewriting the query by removing aggregate functions will increase the performance tremendously.
| Original Query | Improved Query |
|---|---|
| SELECT * FROM SH.sales WHERE EXTRACT (YEAR FROM TO_DATE (time_id, ‘DD-MON-RR’)) = 2001 AND EXTRACT (MONTH FROM TO_DATE (time_id, ‘DD-MON-RR’)) =12; | SELECT * FROM SH.sales WHERE TRUNC (time_id) BETWEEN TRUNC(TO_DATE(‘12/01/2001’, ’mm/dd/yyyy’)) AND TRUNC (TO_DATE (‘12/30/2001’,’mm/dd/yyyy’)); |
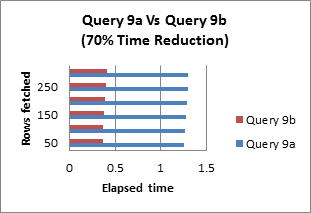
Query 10: Remove any redundant mathematics
There will be times when you will be performing mathematics within an SQL statement. They can be a drag on the performance if written improperly. For each time the query finds a row it will recalculate the math. So eliminating any unnecessary math in the statement will make it perform faster.
| Original query | Improved query |
|---|---|
| SELECT * FROM SH.sales s WHERE s.cust_id + 10000 < 35000; | SELECT * FROM SH.sales s WHERE s.cust_id < 25000; |
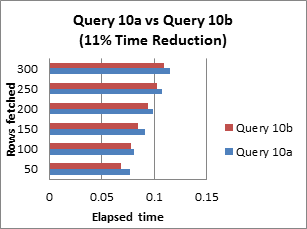
Query 11: Use ‘regexp_like’ to replace ‘LIKE’ clauses
| Original query | Improved query |
|---|---|
| SELECT * FROM table1 WHERE lower(item_name) LIKE ‘%samsung%’ OR lower(item_name) LIKE ‘%xiaomi%’ OR lower(item_name) LIKE ‘%iphone%’ OR lower(item_name) LIKE ‘%huawei%’ | SELECT * FROM table1 WHERE REGEXP_LIKE(lower(item_name), ‘samsung|xiaomi|iphone|huawei’) |
Query 11: Use ‘regexp_extract’ to replace ‘Case-when Like’
| Original query | Improved query |
|---|---|
| SELECT CASE WHEN concat(‘ ‘,item_name,’ ‘) LIKE ‘%acer%’ then ‘Acer’ WHEN concat(‘ ‘,item_name,’ ‘) LIKE ‘%advance%’ then ‘Advance’ WHEN concat(‘ ‘,item_name,’ ‘) LIKE ‘%alfalink%’ then ‘Alfalink’ … AS brand FROM item_list | SELECT regexp_extract(item_name,'(asus|lenovo|hp|acer|dell|zyrex|…)’) AS brand FROM item_list |
Query 12: Always order your JOINs from the largest tables to the smallest tables
| Original query | Improved query |
|---|---|
| SELECT * FROM small_table JOIN large_table ON small_table.id = large_table.id | SELECT * FROM large_table JOIN small_table ON small_table.id = large_table.id |
Query 13: Always “GROUP BY” by the attribute/column with the largest number of unique entities/values
| Original query | Improved query |
|---|---|
| select main_category, sub_category, itemid, sum(price) from table1 group by main_category, sub_category, itemid | select main_category, sub_category, itemid, sum(price) from table1 group by itemid, sub_category, main_category |
Query 14: Use Max instead of Rank
| Original query | Improved query |
|---|---|
| SELECT * from ( select userid, rank() over (order by prdate desc) as rank from table1 ) where ranking = 1 | SELECT userid, max(prdate) from table1 group by 1 |
Other Optimization Technique
- Choose Datatype wisely: Using
Varchar(10)for storing fixed-length data (like Mobile Number) will incur a 20% higher query executing penalty when compared to usingchar(10)for fixed-length data. - Avoid using implicit conversion: When a query compares different data types, it uses implicit datatype conversion. Hence, in queries, one should avoid comparing different datatype columns and values.
- Avoid using
DISTINCTandGROUP BYat the same time: If you already haveGROUPBY in your query, there is no need to havingDISTINCTseparately. - Avoid using Order by in the Sub-query: Ordering in sub-queries is mostly redundant and leads to significant performance issues.
- Minimize use of SELF Joins: Self-joins are computationally more expensive and can be replaced with the Window function in many cases.
- Don’t join tables with OR conditions: It can be optimized by using UNION ALL in place of OR-based joins.
- Avoid join with not equal condition: When a query joins with NOT EQUAL the operator searches all rows and uses a full table scan which is highly inefficient.
- Avoid Full-Text Search: When a query searches for keywords with a wildcard in the beginning it does not utilize an index, and the database is tasked with searching all records for a match anywhere within the selected field. Hence, if needed prefer to use wildcards at the end of a phrase only.
- Use approx_distinct() instead of count(distinct) for very large datasets
- Use approx_percentile(metric, 0.5) for median
Query optimization is a common task performed by database administrators and application designers in order to tune the overall performance of the database system. The purpose of this paper is to provide SQL scenarios to serve as a quick and easy reference guide during the development phase and maintenance of database queries. Even if you have a powerful infrastructure, the performance can be significantly degraded by inefficient queries. Query optimization has a very big impact on the performance of a DBMS and it continuously evolves with new, more sophisticated optimization strategies. So, we should try to follow the general tips mentioned above to get better performance of queries. Optimization can be achieved with some effort if we make it a general practice to follow the rules. The main focus was on query optimizations.
Please follow our other blogs related to SQL:
0 Comments